Creating a Scraper for Multiple URLs Using Regular Expressions
Important Note: The tutorials you will find on this blog may become outdated with new versions of the program. We have now added a series of built-in tutorials in the application which are accessible from the Help menu.
You should run these to discover the Hub.
NOTE: This tutorial was created using version 0.8.2. The Scraper Editor interface has changed a long time ago. More features were included and some controls now have a new name. The following can still be a good complement to get acquainted with scrapers. The Sraper Editor can now be found in the ‘Scrapers’ view instead of ‘Source’ but the principle remains funamentally the same.
In this example we’ll redo the scraper from the previous lesson using Regular Expressions. This will allow us to create a more precise scraper, which we can then apply to many URLs. When working with RegExps you can always reference a list of basic expressions and a tutorial by selecting ‘Help’ in the menu bar.
Recap: For complex web pages or specific needs, when the automatic data extraction functions (table, list, guess) don’t provide you with exactly what you are looking for, you can extract data manually by creating your own scraper. Scrapers will be saved on your computer then can be reapplied or shared with other users, as desired.
First, Launch OutWit Hub then open in the Page view:
http://en.wikipedia.org/wiki/Leading_firms_by_activity

In the page view you will see a list of leading firms by activity. Lets make a report detailing the company information for each of these firms.
Traditionally, you’d have to click on each link, then copy and paste the information into an excel spreadsheet, but with the scraper function we’re going to save a lot of time and energy.
If you click on the List view you can see a list of all the URLs and their related companies.

Select a random company to get started, lets say Toyota. Double click on the link for Toyota and you’ll see that you are redirected to the Toyota article in the page view. On the right there is a box with the company information and logo. This is what we’ll use to populate our spreadsheet for each company contained in the original list.

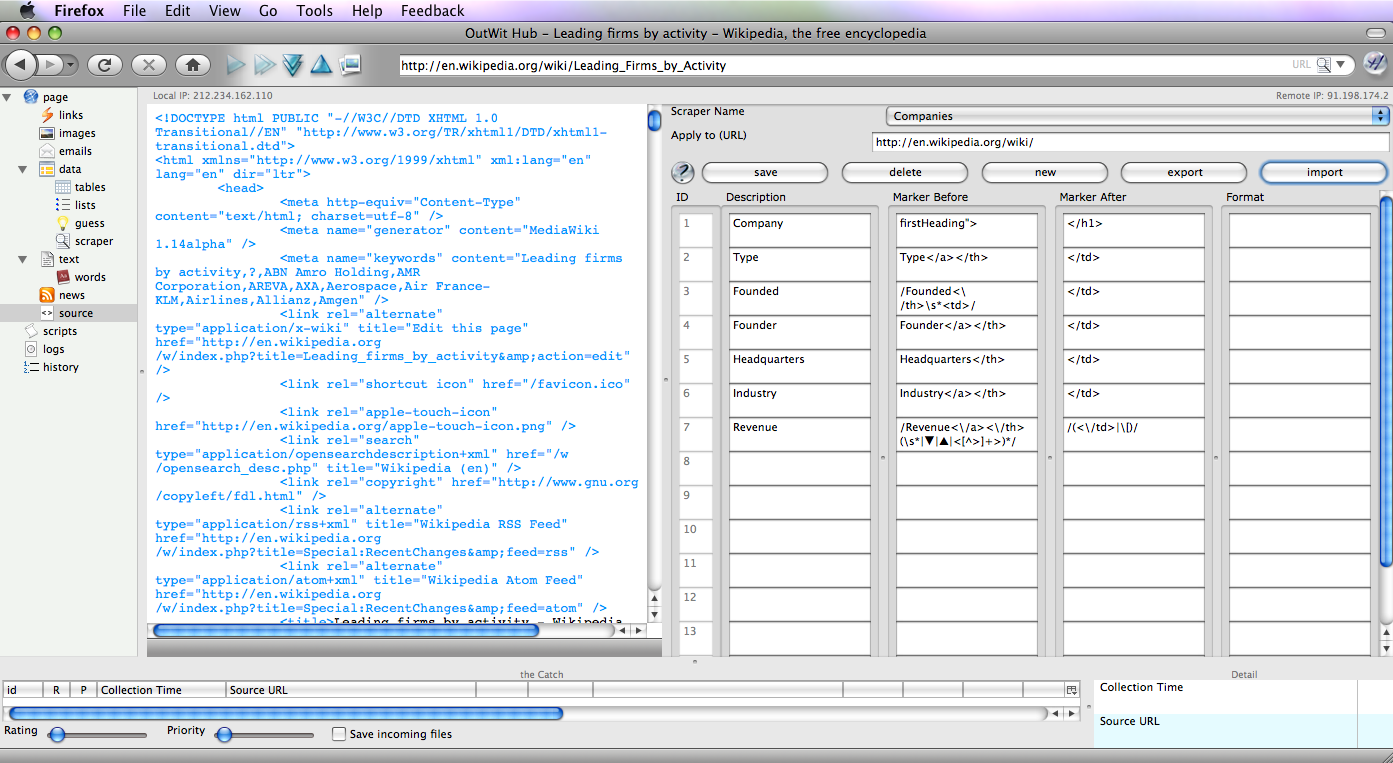
Click ‘Source’ (‘Scrapers’ in v.0.8.9 and later) on the left-hand side view list to open the scraper. Then click New and the box below will appear asking you to enter a URL that satisfies: “scraper will be applied to URLs starting with.” For this sample use: http://en.wikipedia.org/wiki/. You will then be asked to name the scraper: Enter your title and click OK.

If you have already created a scraper for this URL you will see an error: ‘A Scraper for this URL already exists.’ To create a new scraper with the same URL click Delete then New in the scraper menu. Be sure that you have exported your original scraper before clicking delete or you will lose all of your work. Instructions for exporting a scraper are found at the end of this document.
The first column will be named Company, so enter that in the description field. In the Source Code Box you can see Toyota in black, which is the value that we want to populate this field. The text strings in black are the values that appear on the website and when we use the scraper they are the only values that will appear in our results. We need to take the most logical markers both preceding and following Toyota. Now there is no exact way to say how much of the text before or after the value you’ll need to use. You want the Marker Before to be specific and not be repeated in the rest of the document. This will ensure that you will get the correct value when applying the scraper to multiple websites. In our example, firstHeading”> is quite specific so copy & paste that into the Marker Before field. If the Marker Before is unique then the Marker After can be less specific. </h1> will do the trick.

To be absolutely sure the marker is unique, you can use the find command to search the document for the number of instances of the value firstHeading”>. (If Cmd-F/Ctrl-F do not open the Find Box click in the source code box to give it the focus and try again)

Now lets see if this works. Press Save, then click Scraper in the view list, then hit Refresh in the scraper view.
The next few fields are fairly simple so try them out on your own. The column names will be: Type, Founded, Founder, Headquarters, and Industry.

The final field is going to be a bit tricky and will require RegExps. Before we begin lets add a Revenue field with the values: Revenue</a></th> as the Marker Before and </td> as the Marker After and run our scraper. Click Save-Scraper-Refresh.

As you can see there are a lot of unwanted characters (▼[1] [2] [3] [4]). Lets use RegExp to remove them.
Here is a brief explanation of the RegExps that we will use in our scraper:
- The ( ) define the scope and precedence of the operators contained within them
- You must begin and end each expression with a forward slash. (The Format field is always interpreted as a RegExp, even if not marked with slashes)
- Characters, such as: .$*+-^\(){}[]/ should be escaped when you are representing the character itself and not part of the syntax. To escape any of those characters, place a backslash \ before the character you want to be taken literally
- Use the pattern \s* to match a succession of zero or more white space characters, tabs, returns, etc.
- | means “or”: it matches if either the expression before or after it are found
- Use the pattern [^>]+> to match a succession of one or more characters until the next >
- The character * matches zero or more instances of the preceding element
- The character + matches the preceding element 1 or more times
Based on these guidelines, the Marker Before should be: /Revenue<\/a><\/th>(\s*|▼|▲|<[^>]+>)*/ and the Marker After: /(<\/td>|\[)/

You can reference the help Guide in OutWit by selecting Help from the menu bar where you will find a ‘Quick Start Guide’, as well as, general information regarding RegExps. For Help you can also click
in the source view.
We have successfully created our scraper, but now we need to apply it to all the URLs from our list. In the Page view, reload our initial site: http://en.wikipedia.org/wiki/Leading_firms_by_activity. Then select the List view, highlight the links for the companies, right click, and select “Apply Scraper to Selected URLs.”

In the List view select only the values that relate to the links for the companies. (At the time of publication it was rows 62 to 199.)
Right click and then select “Apply Scraper to Selected URLs.”
Now we can go to the Scraper view and see our list loading. If it is not loading, then hit ![]()
To Save the results in an Excel file: Select all (Ctrl-A or Cmd-A). Then Select File and “Export Selection As.” Finally, chose a name, designation for your file, and click Save.

You can also apply the scraper to a series of pages within a website . In the Scraper view you can unselect ‘Empty’ and then select ‘Catch Selection’.
Now you can use the Browse Function
to catch selections from different pages in the Website. You can then select all in your catch and export the work. Click here for a tutorial on Auto Browsing.

You can see that OutWit Hub has successfully created our spreadsheet and removed the unwanted characters.

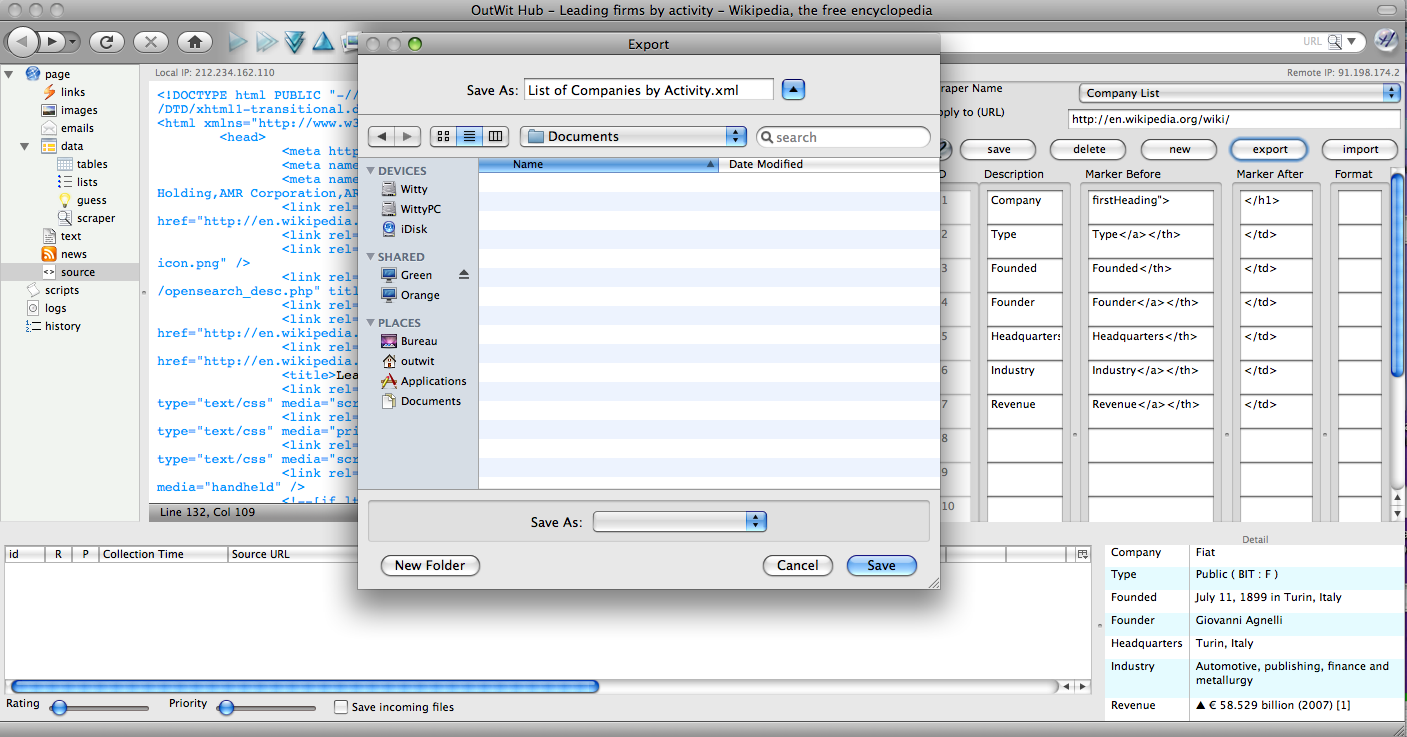
We have one last and very important step to complete. Return to the Source view and click Export. Then chose a name and designation for your file.
It is very important that you export your scraper if you plan to use it again or to create additional scrapers for the same URL. Remember that when we were creating our scraper we applied it to the URL: http://en.wikipedia.org/wiki/. In the future, if you create another scraper for Wikipedia you will also have to use this URL. If you were to do so the new scraper would replace the existing one and all your work would be lost. By exporting and then importing your work you can create many scrapers for the same URL.
To reload a scraper click Import, select your file, then Open.

Occasionally after importing your scraper, it may not appear. You will then have to select it from the drop down box where the Scraper Name is located.

{kind=link}
{kind=link}
This completes our tutorial, and, as always, we welcome any questions or feedback. We couldn’t do this without you.
by jcc
Tags: extract data, Mult URLs, Outwit Hub, RegExp, scraper, Web Harvester
December 24th, 2008 at 5:29 am
What does it cost to build one of these scrapers made and cn you specify your needs in it or forn it?
Thanks
January 7th, 2009 at 2:22 am
The application is very useful. It saves me literally months of time to collect my data, not to mention the strain on my fingers and hands with manual collection of data.
Thank you, thank you, and thank you.
To be useful, i would like to point out a few problems that i experienced with OutWit, which might be helpful with your future development or documentation.
1. Once i set up the Scraper, it seems that i could not edit the markers. During my usage, i tried to change the markers to experience different way to retrieve the same data set, but once it is changed, the whole scraper does not work. i have to delete it and start all over again. it initially took me more than one hour to figure this out. for an impatient user, he might just think that your program does not work.
2. the way the program handles the Before Marker could be more robust? for example, if the marker is too longer (i don’t know if there is actually a limit to the length of the string), the scraper doesn’t seem to work. a longer marker of course will narrow down the data, and it is more convenient for the users.
again, it is a great program. love it.
January 18th, 2009 at 7:38 pm
I really enjoy your application. Though I am really confused on how to have outwit grab data and not strip out all the html on some requests. On all the areas that I need it to strip out the html coding it does this automatically by default and looks really nice. The trouble is when I want to pull just a single link out of a page that is in a table. If I tell it to grab info between and it comes back with just the link name instead of the url.
Are there any switches or reg exp or anything I can use to tell outwit to keep the html intact on one of the scraper queries?
January 27th, 2009 at 4:41 pm
Is it possible to scrape multiple URLs when the “see next page of results” command is based upon a form submission button rather than a hyperlink?
February 2nd, 2009 at 2:12 pm
For the moment, no but I have passed this along to our developers for consideration in future updates.
February 24th, 2009 at 10:54 pm
My outwit is very slow during the “wikipedia” tutorials – is it normal? Even to adjust the dimension of some windows is really slow.
February 24th, 2009 at 11:10 pm
I am confused about the Auto Browse. The site I want to scrape (a small directory) lists a Search Results page (all the listings in the directory, about 1,000) with 10 listings per page and with a next sign -> and page numbers to go to other pages. Outwit does not see the the next pages links (the Load Next Page and Auto Browse buttons are not active).
More so, the page results is not the page I want to scrape. It only shows a few info about companies and each company has a Details link which opens a new browser page (that’s what I want to scrape).
I am wondering if such a site can be scraped with your software.
February 24th, 2009 at 11:14 pm
Is there any software that translates pieces of text into Regular Expressions? It would be amazing if Outwit would have such a “translator” incorporated.
March 2nd, 2009 at 12:45 pm
-The speed of OutWit Hub will vary based on your system, connection, and the data you are trying to extract. It can be a bit slow at times, and this is something we are always trying to improve.
-Depending on how the Webpage is designed, the Hub will not always recognize a series. Again this is something we are working on, but it is quite difficult and may take some time.
-If the page does not contain the information that you want to scrape but instead contains links to the information, go to the List view and select the items you want to scrape, then right-click and chose ‘Apply Scraper to Selected URLs.’
-This is the response from the developers per your request for a translator:
here are two ways to understand your question:
1) in the textboxes of the scraper editor, we could escape reserved characters of the current selection (which is simple and could already be interesting), or
2) with a multiple selection or a whole column in a table, for instance, we could try to build a regular expression matching all the elements (which is a little less simple, but partially done internally in our program, already)
The latter will take more time to perfect, but it is a great idea and we’ll definitely add both in next versions
March 4th, 2009 at 1:48 am
First of all I love this tool and very excited to be living in the world where there are such tools available.
OutWit is working amazingly well except one thing which is killing its purpose for me. When I am on search results page with 20 records per page, OutWit can click page number links fine to go to next page using auto explore option but every row in results page has “More Info” link that I need to click to go to propduct details page that I need to scrap basically. But OutWit stays one layer above and if I say to dig the page, it starts clicking page numbers and keep going instead of clicking individual records. Is there any way to do that?
There are 3,000 + records in search so there is no possibility of manually navigating between links and asking OutWit to go to next page to get details. Thanks!
March 6th, 2009 at 3:27 pm
Спасибо наконец то нашла то что хотела прочитать тут. Кстати у меня есть рисунки на эту тему. Куда можно скинуть? Ещё раз спасибо ! 🙂
March 18th, 2009 at 2:34 pm
Hello all!!!
I’ve a question, I tried to define “| OR” enclosed in “//” but it doesn’t work. Please explain how to define OR condition to be given in “before marker” or “after marker” fields.
March 20th, 2009 at 5:43 pm
Try writing it like this: /(toto|titi)/
March 23rd, 2009 at 8:02 am
Dear Outwit team,
I am actually working for an IT company interested in scraping contact details from a website (all legal).
I followed the tutorials of the outwit blog, creating my own scraper with appropriated mark-ups. But when I click on the extractor link, and refresh the web page, the extractor window remains blank. The guess window is showing the right data though. Have you encountered that issue before? What should I do?
Thank you in advance for your assistance.
Regards,
Guillaume
March 27th, 2009 at 12:10 pm
Hello outwitters!!!
I’m having a problem, I’ve created a scrapper for a website and it works fine. But when I apply the scrapper to multiple URLs, it returns nothing and go not-responding OR return results for only 1 field while 2 or more fields are defined.
Can you please help me out with this thing?
And Can you please upload a tutorial in which you cover “pagination”?
Many thanks, Outwit Hub is a great effort!
-Waqas Shabir
March 27th, 2009 at 12:16 pm
Hello outwitters!!!
I’m having a problem, I’ve created a scrapper for a website and it works fine. But when I apply the scrapper to multiple URLs, it returns nothing and go not-responding OR return results for only 1 field while 2 or more fields are defined.
Can you please help me out with this thing?
And Can you please upload a tutorial in which you cover “pagination”?
Many thanks, Outwit Hub is a great effort!
-Waqas Shabir
April 15th, 2009 at 7:52 pm
I have the same problem as Waqas, I think. I have set up a scraper which works when applied to a single page, but when i go to the main page which contains the list of URLs I want to browse through and then select those links and hit apply Scraper to URLS, my result only comes up with 2 out of 7 fields.
April 16th, 2009 at 11:57 am
We have come across instances where the scraper will not allow you to apply it to multiple URLs or browse through selected URLs. We are currently working on this issue and it will be corrected in future updates. Until then, if you could drop us an email via the Feedback menu and be sure to give the URL and which data you are trying to extract, it would be really helpful. Then we can use these examples to improve the program. Thanks for your support and patience.
April 28th, 2009 at 7:50 am
I am unable to extract URL’s when I create a scraper. For example, perhaps the page i want to scrape has a list of names, and websites linked to them. Outwit simply ignores/deletes any URLS I try to copy. am I missing something?
April 28th, 2009 at 9:49 am
nevermind. the program just needs a little help on usability, and trying to move between projects/scrapers / creating new ones. anyways, complicated for me to explain here
April 28th, 2009 at 9:50 am
OUTWIT IS THE BEST FREE SOFTWARE OF THE YEAR!!!!
May 4th, 2009 at 10:55 pm
Great tool. I’ve found it invaluable.
How about creating a wizard for inexperienced users ?
May 7th, 2009 at 2:40 pm
@AnonDaBomb: Thank you! If you have problems, send us a mail with the complete example/url/scraper you are trying to do.
@Financial Professional: Thanks. You can find some tutorials on this blog, or inside outwit-hub (help menu).
May 10th, 2009 at 10:37 am
Спасибо, люблю читать ваши посты очень интересно
June 21st, 2009 at 12:11 pm
Hi,
I am interested in creating a scraper program for gathering information from this site, but i don’t know how to start. I would by putting in a start date of say “06/04/2009” thru “06/04/2009” then click SEARCH. Then it would take me to the next screen where i would click on the first of the BUSINESS NAME hyperlinks to take me to the next page where the information i need is located with corresponding column names. I will repeat this for all the BUSINESS NAME hyperlinks listed. Can you write me a scraper to help me accomplish this task. I like what i see of the program otherwise, but i just need a start on how to set this scraper up. Thanks!
August 4th, 2009 at 10:43 am
[…] more advanced tutorial, we will learn how to remove the unwanted characters using RegExp. Click here to skip to the next […]
September 1st, 2009 at 10:34 am
Great tool. Would you mind provinding a complete documentation of the Regular Expression syntax that you are supporting? Are they “Outwit-specific” RegEx or are inspired from one of the traditional RegEx (GREP, BNF…)? Thanks much
September 1st, 2009 at 11:01 am
Hi,
You will find more informations on the regular expressions used in OutWit at https://developer.mozilla.org/en/Core_JavaScript_1.5_Guide/Regular_Expressions.
Cheers,
pr
September 1st, 2009 at 1:50 pm
Thanks. I also have just realized that a nice summary exists in Outwit Help (under RegEx quickstart tab)
September 3rd, 2009 at 3:01 pm
Is their a way to have the scrapper search multiple links down. Right now, it appears that I have to go to EVERY link and set up those to be scrapped when I want the scrapper to go down maybe 4 or 5 links from the starting page.
September 3rd, 2009 at 3:12 pm
Hi Steve,
You can select multiple URLs in the link view for example (but it can be on any view containing URL), right click and “Apply scraper to selected URLs”.
This will apply your current loaded scraper on all of the pages.
Cheers,
pr
September 3rd, 2009 at 6:18 pm
pr,
That I can do.
What I need it to do is start and those links, and look at the links in the next page down and so on.
Also, can you use wildcards in the url links when I set up the url to search?
thanks!
September 4th, 2009 at 11:10 am
Hi,
What you need is a coming feature that will give you the possibility to combine browse through a list of URL, browse through next pages, and dig.
So you’ll need to wait for the next release.
You cannot directly use wildcards in URLs, but you can generate URLs with wildcards, for example in the links view : select one or more URLs, right click, “Insert rows…”.
Cheers,
—
pr
September 4th, 2009 at 2:45 pm
Kewl!
Any idea when the new release will be available?
Thanks!
Steve
October 5th, 2009 at 10:36 pm
We may have found a bug.
I created a regular html page with a list of the websites I want to scrape.
There are 338 websites I’m scrapping.
It is giving me duplicate data on some of them.
I’ve checked out the pages, and the data should be different.
Any thing I could be doing wrong?
Thanks!
FYI, really love how this works!!!!
October 6th, 2009 at 2:49 pm
Steve,
Answered you by email.
Please send us your test case so that we can found the bug.
Regards.
November 2nd, 2009 at 7:26 am
Please explain if there is any way to ‘generalize’ the URL that a scraper is to be applied to, perhaps by regular expression? If so, please give a coded example.
Here is a specific example of why I ask this question. A website is designed with subdomains, and within those subdomains are pages that have the same layout and data that is wanted. Like this:
http://companyA.domain.com/info1.html
http://companyB.domain.com/info3.html
http://personX.domain.com/info-pers.html
So, when I first create the scraper, I would like to be able to say it applies to urls like this:
http://*.domain.com/info*.html
Can this be done, and if so, how?
If not, is there a way to duplicate a scraper? Say, import it and then rename it? (Tedious, but less tedious than rewriting it).
Thanks for an excellent program!!
November 2nd, 2009 at 7:29 am
Here is a suggestion, also. Allow multiple scrapers to be loaded for the same URLs provided they have unique names. Then ask the user to choose a scraper by name when/if there is a conflict. If a user finds this tedious, that user could choose to ‘unload’ the conflicting scrapers.
November 23rd, 2009 at 8:26 am
You will find this in the next version (v. 0.8.9). OutWit Hub will include a scraper manager that should help a lot those who use scrapers extensively.
November 23rd, 2009 at 8:30 am
Scraper URLs will accept regular expressions in version 0.8.9. (As well as duplication etc.) Hope you enjoy it.
January 20th, 2010 at 6:53 pm
Beatifull product. Question: I have a website structured like
Page 1 Containing links to various products
|
|_ Linked page, containing a tab with a link to second page (some details)
|
|_ Second page (rest of details)
The URL for the secondpage is different and not reachable from Page 1, can I somehow reach the second detailpage
January 24th, 2010 at 6:38 pm
We are working on this problem. Currently, I guess the only ways to do this are pretty indirect. You can do it in two passes, first scraping the data of the first page as well as the second page urls then applying a scraper to the second page urls, making sure that you grab a product name or id that will allow you to reconcilate the two batches of data.
August 24th, 2010 at 9:46 pm
Hello, I understand that Outwit right now has a 100 link restriction on the data scraping tool, how do I lift the 100 link restriction? Is there a premium version of the software that I must pay for? Thank you
August 25th, 2010 at 6:19 pm
Hello,
You can ask for a beta key for the future pro version using the “upgrade” menu.
Regards,
October 12th, 2010 at 11:52 pm
One thing I would find extremely helpful is the functionality to use, say, a list of URL’s to be scraped which are already collected. For instance, the ability to import a .xls file w/ a list of URLS, and then execute as scraper on that.
October 13th, 2010 at 12:05 am
Yes Jacob, you are right: we will add import functionalities as soon as possible. However, in the meantime, you can already import URLs by gathering them in a text file and opening the .txt file in the Hub. As for URLs that are extracted by the Hub itself, you can easily create a directory in queries with them and use this directory for any number of things (in a macro, or, with a right-click, browsing through them, applying scrapers to them, etc.). Please have a look at the help if you are unclear on these features.
PS. We will release in one of the coming updates, an integrated Wizard/Tutorial system which will finally replace the outdated tutorials that can be found on this blog and on the Web.
Cheers,
JC