Create your First Web Scraper to Extract Data from a Web Page
Important Note: The tutorials you will find on this blog may become outdated with new versions of the program. We have now added a series of built-in tutorials in the application which are accessible from the Help menu.
You should run these to discover the Hub.
Find a simple but more up-to-date version of this tutorial here
This tutorial was created using version 0.8.2. The Scraper Editor interface has changed a long time ago. Many more features were included and some controls now have a new name. The following can still be a good complement to get acquainted with scrapers. The Sraper Editor can now be found in the ‘Scrapers’ view instead of ‘Source’ but the principle remains funamentally the same.
In many cases the automatic data extraction functions: tables, lists, guess, will be enough and you will manage to extract and export the data in just a few clicks.
If, however, the page is too complex, or if your needs are more specific there is a way to extract data manually: Create your own scraper.
Scrapers will be saved to your personal database and you will be able to re-apply them on the same URL or on other URLs starting, for instance, with the same domain name.
A scraper can even be applied to whole lists of URLs.
You can also export your scrapers and share them with other users.
Let’s get acquainted with this feature by creating a simple one.
2. Choose the Web Page to Scrape
Let’s use this example of an HTML list: http://www.outwit.com/support/help/hub/tutorials/GrabDataExample1.html

Type the URL in the address bar.

In our present example, the data could be extracted simply using the ‘List’ view in the data section.
If you don’t see anything in the list view,
reload
the page.
In the ‘Lists’ view, like in most other views, right-clicking on selected rows gives you access to a wealth of features to edit and clean the data.
If the data, as extracted in the list view, is not structured enough for your needs you will have to create a customized scraper for this page.
The Scraper Editor is on the right side of the ‘Source’ view, with the colorized HTML source of the page.

The text in black is the content actually displayed on the page. This colorization makes it very easy to identify the data you are interested in.
Building a scraper is simply telling the program what comes immediately before and after the data you want to extract and/or its format.
So let’s create a scraper for this list.
Click on ‘New,’ type in the URL of the page and a name for your new scraper.

Fill the cells with the most logical markers you find around the different pieces of data (don’t look below for the solution… your computer is watching and you would loose ten points.)
Your first version should logically look like this:
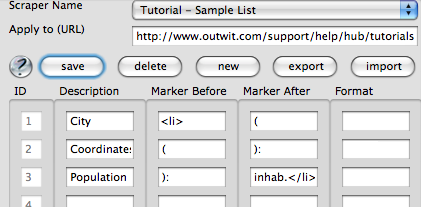
Hit ‘Save,’ and that’s it! You are ready to run your first scraper.
If you now go to the ‘Scraper’ view and hit refresh, the results are there.
They are not bad… but not totally satisfying:

The first row contains text instead of the Coordinates, and the City is missing.
Another look at the source code explains it. The parenthesis ( which is used as the Marker Before Coordinates, appears in a comment hidden in the source code:

You must, therefore, be a little more precise and define the format of the first character that must be found after the marker.
Here, a good way is to use the Regular Expression syntax in the Format field. RegExps can become pretty tricky if you need to find complex patterns, but here, what you want to say is simple: “a string that starts with a digit”.
For this, you need to type \d.+ (a digit \d, followed by a series of one or more characters .+)

Hit Save.
Back to the scraper view, the new result is pretty good.
Reload
One last problem, though, the first city took its continent along with it…

Let’s have a look at the source code one last time.
<li>, our Marker Before City, also appears before the continent.

A simple way, here, is to select all the characters between the beginning of the line and the city name, and copy them into the scraper editor. It makes the marker more specific, and it will keep working because all cities are at the same indentation level:

Our final scraper looks like this:
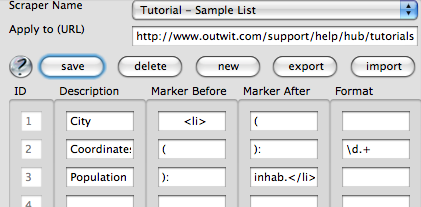
Don’t forget to hit ‘Save’ for indeed we did it!
OK, the present example is not all that exciting and the figures are already out of date. It would almost be faster to do the 15 rows manually.
But, what if the data filled 20 pages and we decided to update the population figures tomorrow?
Better: what if the data was changing every morning, like job ads, sport results, or stock market indices?… No problem, you would simply re-apply your new scraper.
If you want some tips concerning Scrapers and Regular Expressions, you can refer to the “Help” menu.
by jcc
Tags: extract data, harvest web, Outwit Hub, scraper, tutorial, Web scraper
September 4th, 2008 at 4:38 pm
This is a fantastic program. The scraper is exactly what I need.
Here’s my question: The tutorial says you can apply a scraper to a list of URL’s.
But I can’t figure out how to actually LOAD a list of URL’s into the program.
Do I have to individually browse to each page, if I already have my list of URL’s? Or is there a way to load a list of URL’s [say, if they were in a text file, for example] and send the scraper out to browse those pages?
September 5th, 2008 at 9:55 am
Brian,
Thanks a lot for your comment. You are perfectly right! These have been in the to do list for months. You just made their priority climb. Here is what we plan to do:
– Drag & drop to the Page (so that you can drag items from the catch for instance and use them as if it was a Web page),
– Allow to work on documents without a DOM (like a simple text file) as we work on HTML pages,
– Progressively add scripting capacities, so that one can rapidly perform a series of tasks on batches of sources….
September 19th, 2008 at 7:03 pm
I would second the request for a list of URL capability. More importantly I would second the compliment at this fantastic tool. This really fills a hole in tasks that are too large for manual extraction, but too small for building a Perl script from scratch. I think with even basic scripting capability/ ability to apply against a list of URLs, this will be a powerful tool.
October 26th, 2008 at 6:03 am
I third! I love this, there are tons of gui-based scrapers out there, this one is the best.
I would add DOM support to get xpaths of elements, and the ability export them.
November 18th, 2008 at 1:50 am
Hi,
Thanks for this program. I can see it saving me alot of time.
2 questions.
>>
1. Can I extend the “guess” with a scaper?
ie. the guess formats the data into columns,
but there is one column I would like to expand into 3 columns,
can I access the scaper created by the guess and extend it?
That way I can do less work.
Thanks in advance.
>>
2. From the guess there is a column which contains a URL, can we get outwit to follow the url and then further extract the data in the following page.
ie. like an “explore links of this page” but applied to only one/two columns of the table.
A bit like a recursive find with a depth of 1.
Thanks in advance.
cheers
Ed
February 5th, 2009 at 8:25 pm
I was trying to scrape some content that includes tags and brakes but your software is stripping the html. How I can keep the formatting?
February 9th, 2009 at 11:28 pm
i have same problem as Mark, its possible to scrape html tags?
February 10th, 2009 at 5:16 pm
I am sad to say to it, but the answer is no. We agree that this is a necessary feature, however, and are discussing how to add it in a future release. It’s no easy task so this could take awhile. Thank you for your patience and please, keep the questions and/or suggestions coming. We love hearing from our users and couldn’t do this without you.
February 24th, 2009 at 9:23 pm
Followed the tutorial but I got a “Source URL” column. Wondering why?…
In any case – super terrific scraping solution – and it’s FREE! I hope it will stay free and there isn’t another “Catch” in the make 🙂
March 2nd, 2009 at 12:46 pm
The source URL column can be found in many of the views and is always present in the scraper and Catch results.
Thanks for the compliment!
March 21st, 2009 at 8:31 pm
I thought this would be nice to have, but i think your software is geared to the more technically advanced.
March 29th, 2009 at 1:03 am
its really a fantastic tool i sincerely thank the developers of this tool who has created
its a mind blowing tool thank you a lot giving this world a better tool which this world always in need of. apart from all this its free thank you and god bless you
March 29th, 2009 at 1:05 am
i just want to know how to seperate address in different columns like address city state zip code while using scraper please someone help me in this regard thank you
April 17th, 2009 at 9:56 pm
Like Supernova, I need to extract and save one column with address data etc. How to do????
May 7th, 2009 at 2:46 pm
Thanks for you support.
I’m sorry but I don’t understand what you are trying to do exactly. If you created a scraper that doesn’t work (and think it should), just send us a bugreport
May 8th, 2009 at 7:04 pm
Bonjour,
J’apprécie beaucoup votre programme 🙂
J’ai cependant une question.
Quelquefois, la section “devine” ou “table” fait apparaitre exactement le résultat souhaité (et souvent avec liens),
existe-t-il un moyen pour obtenir automatiquement le scraper correspondant ? car je n’arrive pas à obtenir ce résultat parfait. Cela est suffisant pour extraire une seule ou quelques pages, mais j’ai besoin du scraper pour l’appliquer sur une série de liens en chaine (depuis une page texte)
Aussi, quel est le maximum de liens possible dans un fichier texte ? et combien de lignes dans le cash ?
Merci d’avance pour votre réponse
Cordialement.
May 14th, 2009 at 2:33 pm
Bonjour,
Merci pour votre commentaire.
Malheureusement il n’est pas possible pour l’instant de récupérer les scrapers des vues.
En revanche, vous pouvez charger votre fichier texte, décocher “vider” et cocher “ajouter au catch” dans les panneaux de sélection des vues qui vous intéresse, et dans la vue liens, selectionnez les liens, clic droit, “parcourir les liens sélectionnés”.
Il n’y a pas de limite au nombre de liens ou de lignes dans un catch, mais les performances risquent de se dégrader suivant la puissance de votre machine.
Cordialement.
July 1st, 2009 at 1:27 am
[…] For for more information on how to create a custom scraper, see OutWit Technologies’ Create Your First Scraper. […]
July 18th, 2009 at 7:26 am
[…] is a detailed info on creating your first scraper as well as the post where I found this cool […]
July 19th, 2009 at 3:34 pm
[…] возможность написания своих правил для парсинга – Create your First Scraper (инструкция с […]
July 19th, 2009 at 10:35 pm
Excellent program, thank you very much!
July 29th, 2009 at 9:57 am
Hello,
I try to take links (or directly files !) linked in swf player.
There is 2000+ pages, all linked like this :
Can i do it with a scraper or in another way ?
I tried with the scrapper with :
Description : TXT
Marker before : player.swf?file=
Marker after : &action
But it doesn’t make it…
If you can help me….
Thanks a lot !
July 29th, 2009 at 10:42 am
Heyyyyy !!!!
IT WORKS !!! AMAZING !
In my previous question, i didn’t look the right place !
In the Extraction menu (on the left), i had my results !
So for people, if you check “move tho the catch” and “save the files in the catch”, it’s all good !
Men, it’s an incredible work !
August 14th, 2009 at 8:33 am
[…] because in it there is a possibility of writing its rules for [parsing] – Create of your Of first Of scraper (instruction with the […]
September 21st, 2009 at 12:53 am
[…] is a detailed info on creating your first scraper as well as the post where I found this cool […]
February 21st, 2010 at 2:03 am
Hi,
Thanks for the amazing program. I do miss one feature though.
The emails view is good, but lacks the text that is displayed for those emails (Usually the name of the person for which this email belongs).
It could be solved either in the emails view or in the scrapper. But the scrapper lacks the ability to catch the HTML tags, so I can catch the name of the person but not its email.
I would be grateful if you could add one of these features.
March 25th, 2010 at 9:31 pm
I see “;” in place of all the line breaks when using the scrapers. How do we avoid that or remove the “;”? By the way, great tool!
March 26th, 2010 at 11:33 am
Hello and thanks. (Please, do use our feedback form in outwit.com for this type or message, it allows us to keep our bug/wish list up to date.)
We are replacing returns by “;” (after having replaced all “;” by “,” ), to make cut and paste to a spreadsheet easier. It is not a completely satisfying solution but it is a better choice in most cases than simply removing the returns, as it allows you to recover a little of the original layout in the destination program, replacing back “;” by returns. We are adding a “clean text” option (checked by default) in all views of the next version. It means that, if you uncheck it, you will be able to keep html tags like <br> in the scraped text.
Actually, this gave us a pretty simple idea: we will add a find/replace function in all datasheets of a next version. It should help in these cases.
Cheers,
JC
April 22nd, 2010 at 8:32 am
Hi Yigal,
Since the last version, it’s possible to keep HTML tags in scrapers (also in tables, lists). You’ll see a “Clean data” checkbox in the bottom panel, just uncheck it.
We’ll probably work later on getting text in the email view.
Cheers,
May 16th, 2010 at 5:57 am
LOVE this app! Thanks!
Is there a way to catch all of the return from a paged view?
For example, I am working with a search which returns 50 results per page .. but 250 pages.
I’m not quite sure how to have the scraper iterate thru all of the pages.
Can you help?
May 16th, 2010 at 6:04 am
One other observation:
since the scraper saves the target URL, it seems it might be a good idea to have it go to that URL automatically when executed rather than having to copy and paste it into the address field .. ?
May 17th, 2010 at 9:46 am
For this, you can use the right arrow (next) or the double right arrow (browse) if they are active. You can also collect a list of URLs in your catch for instance, select them and use the right click menu option ‘Browse through selected URLs’.
(NOTE: For technical questions, please, do use the feedback link rather than posting a comment to the blog for support tickets to be followed.)
May 17th, 2010 at 9:58 am
@Jim: The Apply to URL in the scraper can be a partial URL, or a regExp or just a string to be found in the current URL for the program to decide if the scraper applies to the page. The idea is that once on a page, simply going to the ‘scraped’ view will execute the process. Imagine you put ‘mySite.com/search?’ in the apply to URL, then the scraper will apply to any result pages on mySite ; in this case, we cannot load the page as we only have a partial URL. Macros, however will allow this in the Pro version.
June 16th, 2011 at 6:28 pm
The automatic scraper does a great job of only placing the text that would be seen on the web page instead of the html code. However, when I build my own scraper, I have to build it where there are numerous html fields in a single capture. hence, the scraper returns both the html code and the text that would appear on the website. I do not want the html code in my catch.
Is there a button when you make your own scraper that will not catch the html code but will select the text that appears on the website?
Thanks,
George
The example is
4
29
184779
HARRIS ESTATE B
013
26-JAN-83
9999
010-10N-13W
1440
BENSON
where I use as the “Marker Before” and as the “Marker After” I just want the text not all the html code like “” or “
June 28th, 2011 at 10:21 am
@George: you can use the “clean data” checkbox in the scraped bottom panel. Please use the contact page for any question/suggestion/bugreport.
September 2nd, 2011 at 12:58 am
Hi,
Great tool…
A quick question– how do you make a list of url’s to be scaped?
Thank you in advance.
September 2nd, 2011 at 7:45 am
If you have the pro version, you can use the ‘queries’ view and create a directory of URLs to be used manually or called in a macro. There are several ways to add URLs to a directory of queries, the drag and drop is the easiest.
If you are using the light version, the best way is simply to put your URLs in a .txt file and open the file with the Hub.
Cheers,
JC
September 2nd, 2011 at 7:32 pm
Thanks JC.
I have opened the .txt file with the Hub. Now about the scraper,
how do you tweak the scraper to scrape the pages?
Thanks again in advance.
September 2nd, 2011 at 7:51 pm
You’ll be able to do all sorts of tweakings after reading the help 🙂
Go to links, select all your URLs, right click on one of them and choose “Browse through selected URLs…” or “Apply scraper to selected URLs…” These are the simplest ways.
But, please, do read the help and do not use this blog for support tickets: We have a perfectly good support system on the site… As it says in red in the comment form you used to type this 😉
Cheers,
JC
September 2nd, 2011 at 8:00 pm
Thanks JCC. Will do!
August 19th, 2012 at 1:10 am
This tutorial got my scrapping a website for a project data I needed. Thank you so much for the details. Worked perfect!
September 26th, 2012 at 9:24 pm
The last entry and archive is a year old. Is this software still operational and is anybody supporting it?
September 27th, 2012 at 8:55 am
The last post was last week, in fact. And yes, it’s still very much operational and supported. This page, however, as it says in red at the top, is about a very old tutorial. You should use the ones built in the Hub instead. Feel free to send us bug reports or suggestion with our contact form.